
1. Intro
안녕하세요. 베이글코드 데이터&AI팀의 엔지니어링 매니저 정현진입니다.
이번에는 Databricks Data Intelligence Day 한국 이벤트 2024에서 발표했던 Databricks SQL Serverless 도입, Redshift와 기존 Databricks SQL Classic 서비스를 대체한 이야기를 해보려고 합니다.
2. Background
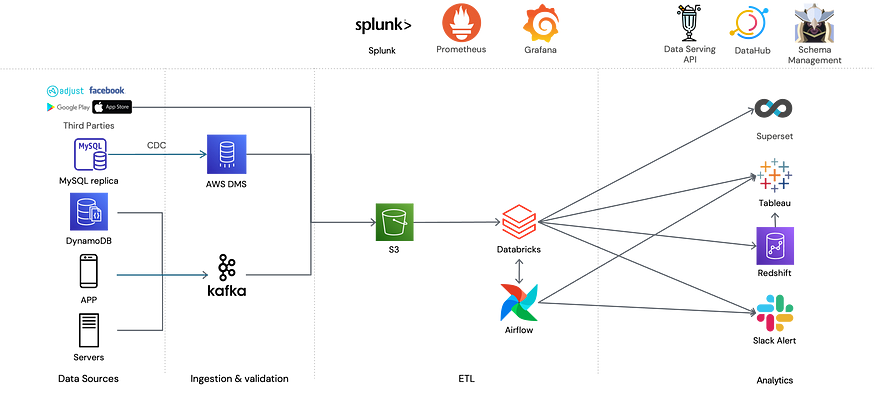
베이글코드의 DATA&AI 팀은 2017년 만들어졌습니다.
초기에는 데이터 양이 많지 않았기에 AWS Redshift 를 통해서 ETL 작업이 진행되었는데요.
이러한 구조는 2018년에 이미 큰 부하를 받게 되어 Databricks를 전면적으로 도입하게 됩니다.
그러나 그 당시에는 Databricks SQL 서비스는 존재하지 않았고, 각 팀의 분석가에게 제공해야 할 Endpoint가 여전히 필요한 상황이었기 때문에 Databricks에서 ETL을 진행한 뒤, Redshift에 sink 하는 과정을 통해서 데이터를 제공했습니다.
당시에도 Redshift가 S3에 있는 External parquet을 읽도록 지원하기는 했지만, 팀에서 사용하기에 너무 느리다는 단점이 있었기에 Databricks에서 처리한 ETL의 다운스트림으로 Redshift로 sink하는 Airflow job을 통해 Databricks와 Redshift가 동일한 내용의 테이블을 보유하도록 설정했습니다.
시간이 지나 프로덕트와 회사가 성장하면서 데이터&AI 팀은 페타바이트급 데이터베이스를 보유하게 됐는데요. 이러한 데이터들을 선별해 Redshift에 매번 업데이트하는 작업은 팀에게 큰 오버헤드로 다가왔습니다.
테이블이 커지면서 Redshift에 데이터를 싱크하는 작업 자체가 오랜 시간이 걸렸고 ETL 결과를 Redshift로 싱크하는 것도 비용이 발생하는 요소였기에 부담으로 다가왔습니다.
또한 오버헤드를 줄이기 위해 여러 자동화 작업을 거쳤음에도 간간이 스키마나 데이터 싱크 과정의 문제가 발생하거나, Databricks에 있는 결과물과의 discrepancy가 발생하여 이유를 찾아내고 고치는 과정을 반복했습니다.
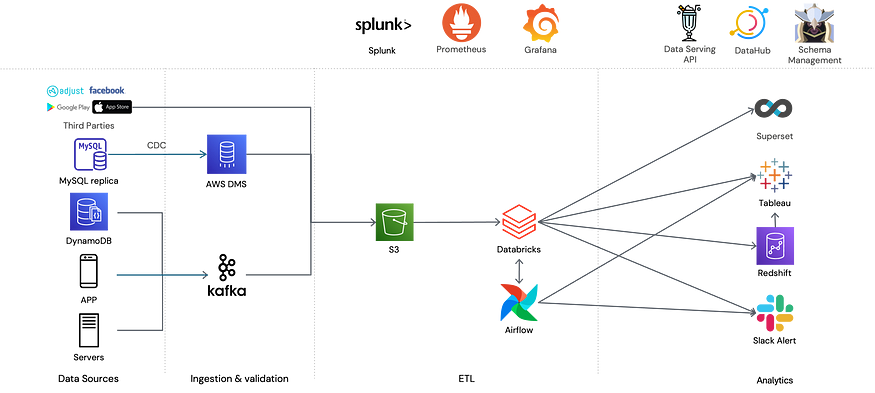
이러한 상황을 타개하기 위해 엔지니어링 팀은 Redshift를 전격적으로 배제하는 작업에 착수했고, 때마침 사용할 수 있게 된 Databricks Serverless SQL을 통해 AWS Redshift를 대체할 수 있었습니다.
3. Redshift to Databricks SQL Serverless
먼저 Redshift를 Databricks SQL Serverless로 마이그레이션한 이야기입니다.
이전에도 Databricks SQL 사용을 고려하긴 했지만 Databricks SQL Classic의 경우 사용할 때마다 인스턴스를 켜거나, 인스턴스를 항상 켜 놓아야 했습니다.
전자의 경우 프로비저닝 하는데 시간이 몇 분 정도 소요되어 사용성이 떨어지는 문제가 있었고, 후자의 경우 인스턴스를 항상 켜 놓는 비용이 적지 않아 쉽게 전환하지 못하고 있는 상황이었습니다.
그러나 Databricks SQL Serverless 의 경우 AWS Lambda와 비슷하게 프로비저닝을 거의 기다리지 않아도 사용이 가능했고, 사용한 만큼 과금되는 구조로 되어있기 때문에 위와 같은 부담 없이 사용이 가능했습니다.
또한, 기존에 보유하고 있던 Superset에 Databricks SQL Serverless 엔드포인트를 연결하는 것 만으로 분석가가 바로 사용할 수 있게 됐고 기존에 쓰던 DataGrip이나 DBeaver과 같은 IDE를 통해서도 접근할 수 있어 큰 문제 없이 전환할 수 있었습니다.
또한 회사 전체의 BI툴인 Tableau 대시보드의 일부 데이터소스들이 Redshift에서 직접 데이터를 업데이트하고 있었는데요.
무거운 쿼리가 필요한 경우 데이터 팀에서 직접 hyper 파일을 만들어 제공하지만 크게 무겁지 않은 경우 분석가분들이 Redshift의 데이터를 이용해 바로 대시보드를 제작하는 경우가 있었는데 Tableau 또한 Databricks SQL Endpoint를 지원하여 어렵지 않게 마이그레이션이 가능했습니다.
Redshift를 Databricks SQL Serverless로 마이그레이션 하면서 개선된 부분들입니다.
- 새로운 스키마나 테이블이 생기면 레드시프트에 싱크하는 job을 만들어주어야 하는 부분이 해소되었습니다. 새로운 이벤트 테이블을 만들었을 때 이 테이블의 스키마를 Databricks와 Redshift에 만들어주는 스키마 관리 시스템에서 Redshift에 테이블을 만들거나 갱신할 때 락이 걸리거나 프리징하는 문제들이 있었는데, Databricks SQL Serverless를 단일 웨어하우스로 운영하게 되면서 이러한 문제가 해결되었습니다.
- Redshift의 스토리지는 클러스터 내부 스토리지로 운영되기 때문에 S3에 parquet 형태로 저장된 ETL 결과물을 Redshift에 싱크해주어야 하는 문제가 있었습니다. 이러한 작업은 Databricks job을 통해서 진행되었기 때문에, Databricks에서도 비용이 발생하고, S3 비용과 Redshift 클러스터 사용 비용이 별도로 발생하고 있었습니다. 이러한 부분도 단일 웨어하우스로 운영하게 되면서 해소되었습니다.
- ETL 결과물을 넣어줄 때 Redshift의 CPU 자원을 소모하기 때문에, Redshift의 성능이 저하되는 문제를 해결했습니다. 또한 업데이트 쿼리와 검색 쿼리가 충돌하면서 쿼리가 블로킹되는 경우가 있었는데, 이런 문제는 어드민 유저가 직접 락을 풀어주는 등 운영 요소가 필요했습니다. 이러한 부분 또한 Redshift를 사용하지 않게 되면서 더 이상 경험할 필요가 없었습니다.
- 권한 관리를 이중으로 해 주어야 하는 문제도 없어졌습니다. Databricks 쪽에서만 ACL 관리를 해주면 되는 구조로 변했기 때문에 이중으로 유저 및 권한 관리를 해 주어야 하는 문제가 없어졌습니다.
- 데이터 웨어하우스의 사일로 문제를 해결했습니다. 데이터 소스가 Databricks에만 존재하기 때문에, 지난하게 팀을 괴롭혔던 discrepancy 문제에서 해방되었고, 데이터를 사용하는 분석가들도, 데이터를 관리하는 엔지니어들도 문제에서 벗어나게 됐습니다.
위와같이 Databricks SQL Serverless를 사용하게 되면서 해당 서비스를 사용하시는 분들도 몇 가지 이점을 가지게 되었습니다. Spark의 다양한 내장함수와 커스텀 펑션을 사용할 수 있게 됐고, 무거운 쿼리들의 실행 속도가 빨라졌습니다. 또한 Redshift에 sink될 때까지 기다리지 않아도 되어 end-to-end 도달 속도가 빨라졌습니다.
Redshift를 Databricks SQL Serverless로 옮긴 것이 모든 면에서 심리스하지는 않았습니다.
Postgresql 기반의 Redshift 쿼리와 Databricks가 사용하는 spark 쿼리의 함수들이 조금씩 다르고, 문법도 조금 다른 부분이 있기 때문에 마이그레이션 코스트가 발생하는 부분이 있었고, Tableau나 IDE를 사용할 때 Redshift 는 대부분의 상황에서 내장 드라이버를 제공하는데 비해 Databricks는 직접 드라이버를 설치해주어야 하는 문제가 있었는데, 이러한 부분은 팀에서 지원이 필요했습니다.
또한 쿼리를 처음 시작하게 되면 딜레이를 경험하는 경우가 종종 있었는데, Serverless이긴 하지만 활성화될때까지 조금 시간이 걸리는 부분이 있기 때문인 것 같습니다.
이러한 단점에도 불구하고 Databricks SQL Serverless를 사용하는 것은 관리적 측면에서 상당한 이점을 가져다 주었으며, 결과적으로 Redshift를 셧다운하게 되어 상당한 비용을 아낄 수 있었기 때문에 비용 측면에서도 큰 절감이 이루어졌습니다.
4. Databricks SQL Classic to Serverless
이번에는 기존에 Databricks SQL Warehouse를 Classic으로 사용하다가 Serverless로 이전한 부분에 대해서 이야기해 보려고 합니다.
Databricks SQL Warehouse 자체는 2020년 도입되었습니다. 베이글코드에서 Usecase를 만든 것은 이를 이용해 Superset을 도입하고 나서부터인데요.
Superset 은 데이터 탐색 및 Visualization 을 위한 오픈소스 플랫폼으로, Databricks와 Redshift에 있는 데이터를 연동하여 한 곳에서 쿼리할 수 있도록 만들었습니다. 이 때 Databricks를 연결하기 위해 Databricks SQL Classic을 사용했습니다.
Databricks SQL Serverless가 소개되면서, Databricks SQL Classic 을 Serverless로 변경하기 위한 작업을 진행하였습니다. 사실 Databricks의 Unity Catalog를 쓰고 있다면, Serverless로 전환하는 작업은 버튼 하나만 누르면 될 정도로 정말 간단합니다. 다만 저희는 여전히 2018년부터 써오던 외부 하이브 메타스토어를 사용하고 있었기 때문에 몇 가지 추가적인 작업들을 진행해줘야 했습니다.
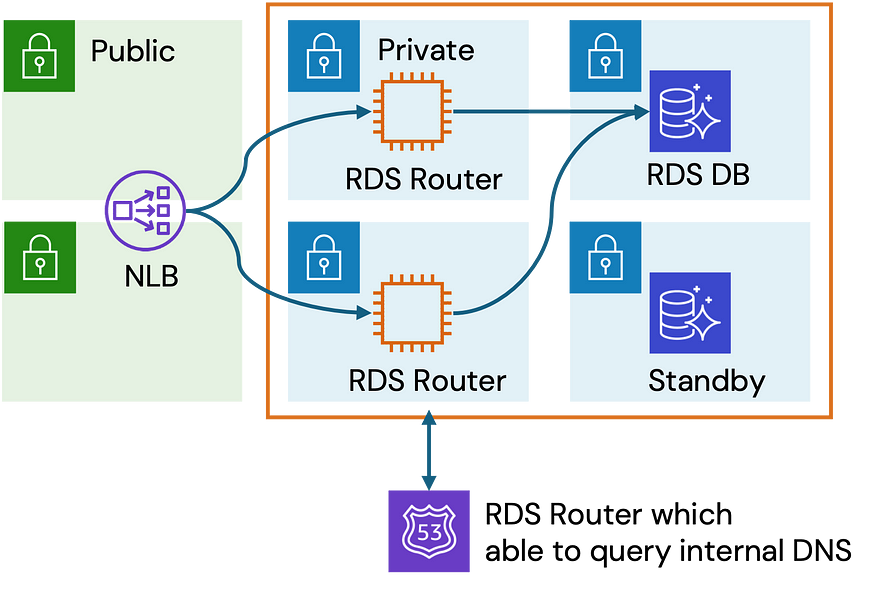
위 그림처럼 연결해주면 되는데, 기존에 Databricks 플랫폼이 연결되어 있던 하이브 메타스토어의 EMR Cluster에 연결하는 게 아니라, RDS에 직접 연결해야 하고
RDS를 바로 열어서 붙이는 것이 아닌 로드밸런서를 별도로 띄워서 연결해야 하는 문제 때문에 SQL Serverless를 처음 사용할 때 꽤 오랜 삽질을 했습니다.
그래도 SQL Classic에서 Serverless로 전환하면서 Superset에서 쿼리할 때 기존보다 빠르게 조회가 가능해졌고, SQL Classic의 경우 팀에서 클러스터를 관리해주어야 해서 가끔 프리징 현상이 생겨서 클러스터 재시작 조치 등이 필요한 경우가 있었는데 Serverless의 경우 인프라 관리 부분이 아예 없다보니 이러한 일들이 사라졌습니다.
또한 SQL Serverless의 경우 SQL Classic의 기능과 더불어 SQL Pro의 기능도 사용이 가능한데, Predictive I/O 지원을 비롯해 퍼포면스 향상 및 편의성 개선이 이루어졌습니다.
Redshift를 종료할 계획을 세우면서 SQL Classic을 이용한 PoC를 진행 중이었는데, 속도가 느린 이슈가 있어서 잘 진행하지 못하고 있던 상황에서 Serverless를 사용해 개선된 속도를 이용할 수 있게 되어 Redshift를 결국 셧다운하고 Databricks로 데이터소스를 일원화할 수 있었습니다.
5. Conclusion
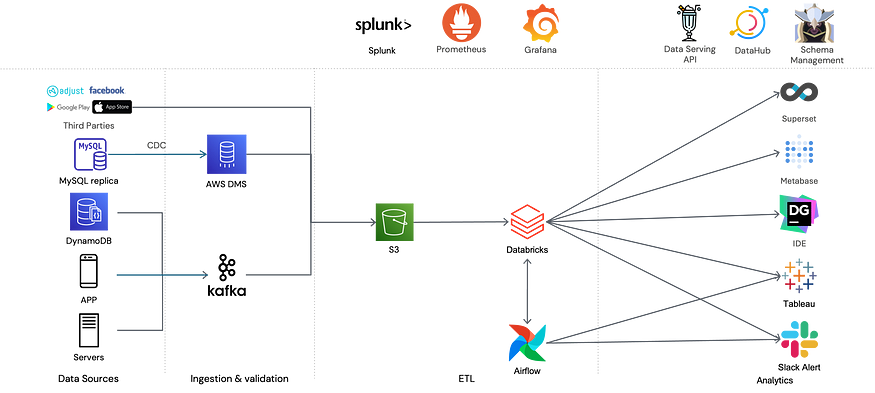
위와 같은 과정을 통해 베이글코드의 데이터 쿼리 백엔드는 대부분 Databricks SQL Serverless로 대체되었습니다. 구조적으로 좀 더 단순해졌고, 데이터를 레드시프트로 밀어넣는 직업을 하지 않게 되어서 데이터 파이프라인의 로드 또한 줄어들었습니다. Redshift 대신 Google Bigquery를 사용하는 조직에서도 Databricks를 쓰고 있다면 이러한 변환을 고민해볼 수 있을 것 같습니다.
Databricks 자체는 Data Lake과 Warehouse를 합쳐놓은 Lakehouse를 표방하고 있는데요.
비즈니스 분석을 위해서는 정형화된 데이터 웨어하우스의 존재가 필요한데, Databricks는 이를 SQL Warehouse라는 기능으로 지원하고 있고, Serverless를 통해 더욱 잘 지원하게 되었습니다.
결과적으로는 AWS 인프라 비용은 줄어들고, Databricks에 지출하는 비용이 늘어나는 형태가 되었지만 전체적으로 봤을 때 꽤 큰 비용 절감을 이룰 수 있었습니다.
베이글코드는 데이터 기반 의사결정을 위해 상당히 많은 데이터를 수집하고 처리하고 분석합니다. 이를 위해서는 데이터에 쉽고 안정적으로 접근할 수 있어야 하는데, 이를 가능하게 하는 토대 중 하나가 데이터 웨어하우스의 존재입니다.
이번 작업을 통해 Redshift 와 Databricks에 각각 사일로될 수 있는 데이터소스를 하나로 모으는 작업을 통해 이러한 데이터 웨어하우스의 신뢰성과 신속성이 증대되었다고 볼 수 있을 것 같습니다.